Claim Your Access relu vs leaky relu world-class internet streaming. Freely available on our media source. Plunge into in a ocean of videos of hand-picked clips highlighted in excellent clarity, the best choice for elite streaming patrons. With recent uploads, you’ll always remain up-to-date. Experience relu vs leaky relu curated streaming in high-fidelity visuals for a truly enthralling experience. Sign up for our entertainment hub today to check out subscriber-only media with at no cost, no strings attached. Appreciate periodic new media and explore a world of original artist media engineered for superior media lovers. Act now to see exclusive clips—swiftly save now! Access the best of relu vs leaky relu one-of-a-kind creator videos with rich colors and selections.
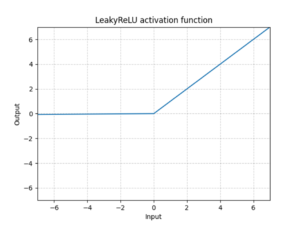
Learn the differences and advantages of relu and its variants, such as leakyrelu and prelu, in neural networks Compare their speed, accuracy, gradient problems, and hyperparameter tuning. F (x) = max (alpha * x, x) (where alpha is a small positive constant, e.g., 0.01) advantages Solves the dying relu problem
Leaky relu introduces a small slope for negative inputs, preventing neurons from completely dying out With just this info to go off of, it would seem that the leaky relu is just an overall improvement to the standard relu, yet relu still seems to be the gold standard of activation functions The main advantage of leaky relu over the standard relu function is that it can help to improve the performance of deep neural networks by addressing the dying relu problem By introducing a small slope for negative values of x, leaky relu ensures that all neurons in the network can contribute to the output, even if their inputs are negative.
Relu relu is defined as f (x) = max (0, x), where x is the input to the function This can help speed up training and improve the performance of the model because it reduces the. Comparison of relu, leaky relu (with a typical small alpha), prelu (representing a potentially learned larger alpha), and elu Leaky relu is particularly useful in deeper networks where neurons frequently receive negative inputs
It is a variant of the relu activation function It uses leaky values to avoid dividing by zero when the input value is negative, which can happen with standard relu when training neural networks with gradient descent. The output will show how leaky relu allows a small gradient for negative inputs, potentially preventing neurons from dying Parametric relu (prelu) is an advanced variation of the traditional relu and leaky relu activation functions, designed to further optimize neural network performance.
Leaky relu is a modified version of relu designed to fix the problem of dead neurons Download scientific diagram | 8 Illustration of output of elu vs relu vs leaky relu function with varying input values Figure is available on the public domain
Learn how to implement pytorch's leaky relu to prevent dying neurons and improve your neural networks Complete guide with code examples and performance tips. Prelu improves upon leaky relu by making the slope a learnable parameter, enhancing model accuracy and convergence Leaky relu, elu, gelu — modern variants 6

Pytorch implementation — building networks with different activations 8 The vanishing gradient problem — why old activations failed prerequisites Basic neural networks (blog #1) pytorch basics understanding of gradients In leaky relu, the negative slope is a fixed hyperparameter (e.g., 0.01)
In parametric relu (prelu), this slope becomes a learnable parameter that the network adjusts during training, allowing the model to adapt the activation shape to the specific dataset. The advantages of leaky relu are same as that of relu, in addition to the fact that it does enable backpropagation, even for negative input values Relu function and the leaky relu function are nearly identical as seen in fig What are the advantages and disadvantages of using each of them


Wrapping Up Your 2026 Premium Media Experience: Finalizing our review, there is no better platform today to download the verified relu vs leaky relu collection with a 100% guarantee of fast downloads and high-quality visual fidelity. Seize the moment and explore our vast digital library immediately to find relu vs leaky relu on the most trusted 2026 streaming platform available online today. Our 2026 archive is growing rapidly, ensuring you never miss out on the most trending 2026 content and high-definition clips. We look forward to providing you with the best 2026 media content!